その生成AI、本当に「使える」ツールですか?〜期待と現実のギャップを埋めるRAGの力〜
- 2025年7月17日
- 読了時間: 13分
更新日:1月20日

近年、私たちの日常に「生成AI」という言葉が急速に浸透し、特にChatGPTの登場は、その汎用性と手軽さから大きな話題を呼びました。「これは仕事のやり方を根本から変える!」、「もう調べ物で困ることはない!」と、胸を躍らせてChatGPTを使い始めた方も多いのではないでしょうか。
しかし、実際に使ってみると、期待していたほどの「万能感」を得られず、「あれ?なんか、思ってたよりも役に立たないな…」と感じたことはありませんか?
例えば、
「もっと専門的な情報が欲しいのに、一般的な回答しか返ってこない…」
「最新の情報を聞いているはずなのに、古いデータに基づいた回答が出てくる…」
「うちの会社独自の資料を学習させて質問したいのに、どうすればいいんだろう…」
「結局、自分で情報を調べてファクトチェックしないといけないから、手間が増えただけかも…」
こんな風に感じたことはないでしょうか?
特に、業務で有効的に活用するには、情報の「鮮度」や「専門性」、そして「正確性」が求められる場面ではChatGPT単体での限界を感じるケースが多くあります。
なぜ、このような「期待と現実のギャップ」が生まれてしまうのでしょうか?
その一因は、ChatGPTのような大規模言語モデル(LLM)が、学習済みの膨大なデータに基づいて「もっともらしい」文章を生成する仕組みにあると考えられます。
裏を返せば、学習データにない情報や、リアルタイムで変化する情報、あるいは特定の分野に特化した深い知識を必要とする質問に対しては、期待通りの回答が得られにくいという特徴を持っているのです。
この「もったいない」状況を解決する手段がいくつも考えられてきました。
プロンプトエンジニアリング(PromptEngineering)
最も手軽で即効性のある方法。ChatGPTへの「指示文(プロンプト)」を工夫することで、より的確な回答を引き出す技術。
RAG(Retrieval-AugmentedGeneration)
外部のナレッジベースや最新の情報源から関連性の高い情報を「検索(Retrieval)」し、その情報を基にChatGPTが回答を「生成(Generation)」する手法。実装のハードルが下がってきており、比較的手軽に導入できる。
ファインチューニング(Fine-tuning)
既存のLLM(ChatGPTのベースモデル)に特定のタスクやデータセットを追加学習させることで、モデルの挙動を調整する方法。特定のドメイン知識や表現スタイルをモデルに深く学習させることができる。多大なリソースと専門知識が要求される。
現実的に考えると、
1は社員全員にプロンプトエンジニアリングを教育すべきと考えると腰が重い・・・。
3は追加のデータをそろえることやハイスペックな計算リソースの確保などコスト面から稟議が面倒そう・・・。
と、いうわけで本記事では2つ目のRAG(Retrieval-AugmentedGeneration)について実装入門を紹介していきます。実はRAGの構築を支援するサービスやライブラリが増えており、導入の敷居が下がっているのです。
本記事では、
RAG(Retrieval-AugmentedGeneration)とは?
具体的なユースケース
実装解説
の順で解説していきます。
RAG(Retrieval-AugmentedGeneration)とは?
繰り返しになりますが、簡単にRAGの概要についておさらいしましょう。
RAGは「Retrieval-AugmentedGeneration(検索拡張生成)」の略称です。言葉の通り、「検索(Retrieval)」によって得た情報を基に「生成(Generation)」を行います。
RAGのポイントは、質問内容が大元のモデルが事前に学習していないことであっても、指定した外部の情報源から「検索」して、検索した情報を参照しながら回答を生成する点にあります。
この仕組みが日常業務にどのように昇華されるのか、具体的なユースケースをいくつかあげてみます。皆さんも自分の業務をイメージしながらどう使うことができるか想像してみてください。
具体的なユースケース
社内問い合わせ対応の効率化と回答精度向上
課題:社員の福利厚生、ITシステムの使い方、経費精算ルール、部署内の特定の業務手順など、社内規定やマニュアルに関する問い合わせが多く、担当者の対応負荷が高い。また、情報が散在しており、回答に時間がかかったり、人によって回答が異なったりする。
RAG導入:全ての社内規定、マニュアル、FAQ、過去の問い合わせ履歴、議事録などをRAGの知識ベースとして取り込みます。
効果:社員はRAGを活用したチャットボットに質問するだけで、最新かつ正確な情報を即座に得られるようになります。担当者は定型的な問い合わせ対応から解放され、より複雑な問題や個別対応に集中できるようになります。情報の属人化も解消され、誰でも同じ質の情報を得られるようになります。
具体的な例:新入社員が「有給休暇の申請方法は?」と質問すると、RAGが人事規定を参照し、具体的な手順、申請期間、フォームの場所などを正確に案内する。
契約書・法務関連文書のレビュー・生成支援
課題:契約書や法的文書の作成・レビューには、専門知識と膨大な時間がかかります。過去の判例や自社の法的ガイドライン、関連法規などを参照する必要があり、ヒューマンエラーのリスクも存在する。
RAG導入:過去の契約書テンプレート、自社の法務ガイドライン、関連法規集、判例データベースなどをRAGの知識ベースに格納します。
効果:契約書のドラフト作成時に、RAGが自動で必要な条項を提案したり、不備がないかチェックしたりできます。特定の契約条項に関する質問に対して、RAGが関連する判例や法規を引用して回答することで、法務担当者のレビュー時間を大幅に短縮し、抜け漏れのリスクを低減します。
具体的な例:「〇〇条項における当社の責任範囲について、過去の事例と照らし合わせて解説してください」と質問すると、RAGが該当条項と類似の過去の裁判事例、自社のリスク許容範囲に関するガイドラインを参照して回答を生成する。
顧客サポート・ヘルプデスク業務の品質向上と省力化
課題:顧客からの問い合わせ内容が多岐にわたり、製品の専門知識が必要な場合や、過去のトラブルシューティング履歴を参照する必要がある場合が多い。オペレーターの教育には時間がかかり、新人オペレーターでは対応できないケースがある。
RAG導入:製品マニュアル、FAQ、過去の顧客対応記録、技術文書、トラブルシューティングガイドなどをRAGの知識ベースに格納します。
効果:顧客はWebサイトのチャットボットで、製品の仕様やトラブルに関する質問に対して、RAGが参照した正確な情報を得られます。オペレーターは、RAGが提供する情報を参考にしながら対応することで、迅速かつ的確な回答が可能になります。これにより、顧客満足度の向上、オペレーターの研修期間短縮、対応件数増加に繋がります。
具体的な例:顧客が「〇〇製品のエラーコードXX-YYの対処法は?」と問い合わせると、RAGが製品マニュアルを参照し、具体的な対処ステップと注意点を提示する。
社内に蓄積された資料を元に回答を返す「RAG」のイメージができたでしょうか?ここからはこのような生成AIをどのように作るか、実装例を解説していきます。
実装解説
準備
以下2つを準備していることを想定して以下を実装していきます。
APIキー :OpenAI
実装環境 :GoogleClabratory
PDF :本記事内に用意したあるテキストをPDF化したもの
実装内容の確認
今から「PDFの情報を元に物語の要約を行う」生成AIを実装していきます。
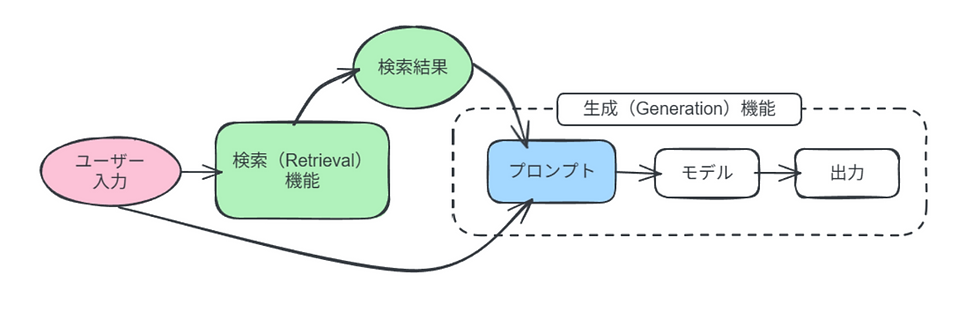
RAG実装に必要な主要なパーツとして、
検索(Retrieval)機能
テキストの読み込み:今回はPDFからデータを抽出
テキストの前処理:読み込んだテキストから不要な部分を除去
テキストの分割:長いテキストを意味のある小さな塊(チャンク)に分割
ベクトル化:テキストを数値のベクトルに変換(埋め込み表現)
データベースの構築:高速に検索できるように数値ベクトルをデータベースに保存する
情報検索器(Retriever)の定義:データベースから実際に情報を検査する機能を持った検索器
生成(Generation)機能
プロンプトの定義:
LLMに「こういうことをして!」と指示するパーツで、Retrievalを参照して回答するように設定する
モデルの定義:LLM本体、今回は物語の要約を行う脳みそ部分
検索(Retrieval)機能と生成(Generation)機能の連結
があります。
これらを下の図のようなイメージで一連の流れとしてつなげるように実装していきます。
APIキーの管理方法
GoogleColaboratoryでAPIキーを使用する際はセキュリティリスクの観点から「シークレット機能」を使用することを強く推奨します。以下の実装についても「シークレット機能」を使用していることが前提となったコードとなっておりますのでご注意ください。
【シークレットへのAPIキー登録方法】
①左のアイコンから「シークレット」を開く。
②「新しいシークレットを追加」をクリック。
③プログラム内で使用する名称を「名前」に入力(GOOGLE_API_KEY)
④所持しているAPIキーを「値」に入力(OpenAIのAPIキー)
⑤「ノートブックからのアクセス」を有効にする

PDFの準備
今回は「桃太郎」の物語に手を加えた文章を使用します。以下の文章を任意のテキストエディタなどでPDF化してご用意ください。※本記事内ではPDFは「test.pdf」というファイル名を使用します。
【桃太郎】
昔々、おじいさんとおばあさんが川で大きな桃を拾いました。家に持ち帰ると桃が割れ、中から元気な男の子が飛び出しました。彼らはその子を桃太郎と名付け、大切に育てました。ある日、浜辺を歩いていた桃太郎は、いじめられている亀を助けました。亀はお礼に彼を竜宮城へ誘い、桃太郎は乙姫様にもてなされました。楽しい時間はあっという間に過ぎ、帰る際に乙姫様から玉手箱を渡されました。地上に戻り玉手箱を開けると、桃太郎はたちまちおじいさんになってしまったのです。
実装
必要なライブラリのインストール・インポート
始めに実装に必要なライブラリを準備します。なお、インストール作業に数分時間を要する場合があります。
!pip install langchain_openai
!pip install -U langchain-community
!pip install pypdf
!pip install -q -U sentence-transformers langchain
!pip install faiss-cpu
from google.colab import userdata
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import re
from langchain.document_loaders import PyPDFLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.embeddings import HuggingFaceEmbeddings
APIキーの取得
「シークレット機能」に登録したAPIキーを「API_KEY」という変数に用意しておきます。
# API_KEYの取得
API_KEY = userdata.get("GOOGLE_API_KEY")
# 取得できていなかった時にメッセージを表示
if API_KEY is None:
raise ValueError("OPENAI_API_KEYが設定されていません。")
通常のLLMの動作確認
外部データを参照しない状態の出力を確認します。以下のコードを実行して私たちのよく知る一般的な「桃太郎」の内容が出力されることを確認しましょう。

本記事ではLLMの実装にLangChainを使用します。LangChainの実装基礎はこちらの記事で紹介していますのでご参照ください。
👈 Click!
# prompt(ChatPromptTemplate)を準備する
prompt = ChatPromptTemplate.from_template("質問: {question}")
# model(ChatOpenAI)を準備する
model = ChatOpenAI(model="gpt-4o-mini", api_key=API_KEY)
# promptとmodelをつないでchainを作成する
chain = prompt | model
# LLMの実行
output = chain.invoke({"question": "桃太郎を100文字以内で要約してください。"})
print(output.content)
検索(Retrieval)機能の実装
続いてRAGシステム内で重要な検索機能を準備していきます。
テキストの読み込み
準備したPDFからデータを読み込んでいきます。PDFはColab上のセッションストレージ内にアップロードしておきましょう。
loader = PyPDFLoader("/content/test.pdf")
pages = loader.load_and_split()
PyPDFLoader():
指定したパスにあるPDFファイルを読み込むための「読み込み機」を定義しています。
loader.load_and_split():
読み込み機を使用してPDFファイルを読み込みます。PDFファイルはページごとに分割され、Documentオブジェクトとしてリスト形式で格納されます。※1ページが1Documentとならない場合もあります。
テキストの前処理
読み込んだテキストから不要な部分を除去します。
def clean_text(text):
text = text.replace("\n", " ")
text = re.sub(r"\s+", " ", text)
text = re.sub(r"^\d+$", "", text)
text = text.strip()
return text
for page in pages:
page.page_content = clean_text(page.page_content)
clean_text():
テキストから余分な文字を置換・削除する関数を作成しています。今回は「改行(\n)」と「スペースやタブなど(r"\s+")」を「半角スペースを1つ」に置換、「数値のみの行(r"^\d+$")」と「テキスト前後の空白」を削除します。
for文を使用してPDFから取り出したDocumentデータごとにclean_text()関数を実行します。
テキストの分割
長すぎるテキストは、そのまま検索すると精度が落ちたり、処理に時間がかかったりすることがあります。そこで、適切な大きさに分割します。分割されたテキストは「チャンク」と呼ばれます。
text_splitter = CharacterTextSplitter(chunk_size=30, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
CharacterTextSplitter():
テキストを文字数に基づいて分割するためのツールを定義します。
chunk_size=30:
何文字で1チャンクとするかを指定する引数です。今回は30文字に設定します。精度の良し悪しに直結しやすい非常に重要な設定のため注意が必要です。
chunk_overlap=0:
チャンク同士の重複する文字数を指定する引数です。今回は重複はしないものとするので0と設定します。
text_splitter.split_documents():
準備した分割ツールを実行します。今回はpagesのテキストを分割します。
ベクトル化に使用する埋め込みモデルの定義
テキストを数値のベクトルに変換(埋め込み表現)していきます。
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
HuggingFaceEmbeddings(model_name="):Hugging Faceというプラットフォームで公開されている、テキストを数値ベクトルに変換するモデルを定義します。今回は「sentence-transformers/all-MiniLM-L6-v2」というモデルを使用します。
データベースの構築
後で関連性の高い情報を高速に検索できるように「ベクトルストア」と呼ばれる特殊なデータベースに保存します。
db = FAISS.from_documents(
docs,
embedding=embeddings,
)
FAISS:高速な類似性検索を行うためのライブラリ。
FAISS.from_documents():分割したテキスト(docs)と埋め込みモデル(embeddings)を指定し、ベクトルストアを作成します。
情報検索器(Retriever)の定義
データベース(db)から実際に情報を検査する機能を持った検索器を定義します。RAGシステムにおいて、ユーザーの質問に対して、関連する情報をベクトルストアから「取り出してくる」役割を担います。
retriever = db.as_retriever(search_kwargs={"k": 3})
db.as_retriever():
ベクトルストア(db)から情報を取り出すための専門の道具(retriever)を定義しています。
search_kwargs={"k": 3}:「"k"」は検索結果として「関連性の高いドキュメント(テキストの断片)から上位何件を取得するか」を指定する数値です。今回はユーザーからの質問に関連性の高い文章の上位3件を取得することになります。
生成(Generation)機能の実装
先ほど準備したRetriever(情報検索器)も使用して生成(Generation)機能を作っていきましょう。
プロンプトとモデルの定義
# プロンプト(指示)の定義
prompt_template = """\
以下の内容を参照して質問に適切に回答してください:
```{context}```
質問: {question}
"""
prompt_rag = ChatPromptTemplate.from_template(prompt_template)
# モデルの定義
model = ChatOpenAI(model="gpt-4o-mini", api_key=API_KEY)
最初に実装したLLMとの違いは「プロンプト」部分にあります。テンプレート内に「retriever」から検索した結果を受け取るプレースホルダ(context)を設定します。
パーツを連結して「Chain」を作成
準備した「情報検索器(retriever)」「プロンプト(prompt_rag)」「モデル(model)」を連結させます。
このChainが実行された時の処理の流れは、
ユーザーの質問(query)が入力される(questionに格納) → 質問に関連する情報検索が行われる(retriever) → 検索された情報をプロンプト(context)に埋め込む(prompt_rag) → 大規模言語モデルがプロンプトに基づいて回答を生成(model) → 回答が出力される
といった順番に実行されます。

# Chainの定義
chain_rag = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt_rag
| model
)
{"context": retriever, "question": RunnablePassthrough()}:プロンプトテンプレート内の「context」と「question」がどのように取得されているかを指定しています。
"context": retriever:これがRAGの「Retrieval(検索)」部分です。contextという名前で、前に作成したretrieverが呼び出されます。
"question": RunnablePassthrough():Chainを実際に実行する時に受け取る質問(query)をそのままプロンプトテンプレートのquestionに渡すという設定です。
作成した「Chain」を動かしてみる
PDF内に書かれた「改変された桃太郎」の内容に準じた出力が返されたら成功です。
query = "桃太郎を100文字以内で要約してください。"
output_rag = chain_rag.invoke(query)
print(output_rag.content)
query:ユーザーの質問です。プロンプトテンプレート内のquestionに渡されます。
ユーザーの質問に対し、PDFから取得した情報を参照しながら、LLMが回答を生成するRAGシステムの一連の流れが完成しました。
「読み込むPDFを変えることで様々なタスクに応用できる」とイメージいただければ幸いです。ぜひ別のPDF、別の質問に書き換えてどのようなことができるか試してみてください。
さて、次回はRAGの精度向上に向けて更に工夫をしていきたいと思います。一歩ずつではありますが、現実問題にフィットした生成AIを作れるようになっていきましょう!
本記事はAI総合研究所として活動するNABLAS株式会社が提供する、法人向けAI人材育成iLectが提供する新講座【ゼロから始めるRAG:開発・改善・運用まで】から一部抜粋したものです。講座内ではさらに実践的な内容を経験豊富な講師・メンターのサポートのもと学ぶことができます。
